Summary
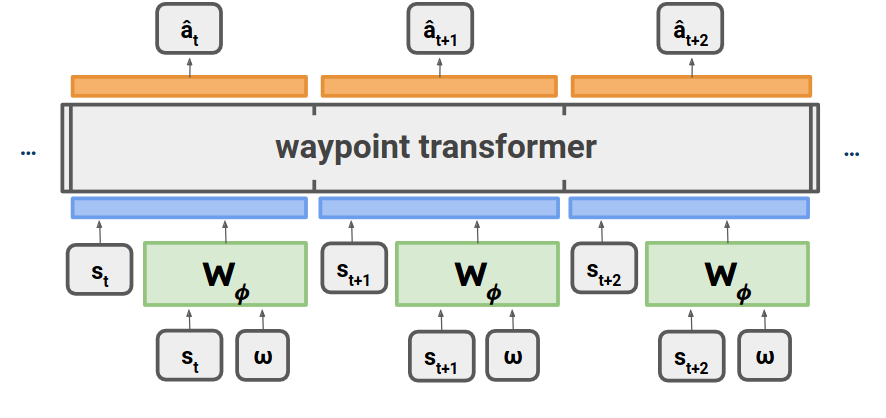
- We propose a novel RvS method, Waypoint Transformer, using waypoint generation networks and establish new state-of-the-art performance, surpassing all existing methods, in challenging tasks such as AntMaze Large and Kitchen Partial/Mixed (Fu et al., 2020). On tasks from Gym-MuJoCo, our method rivals the performance of TD learning-based methods such as Implicit Q-Learning and Conservative Q-Learning (Kostrikov et al., 2021; Kumar et al., 2020), with significant improvements over existing RvS methods.
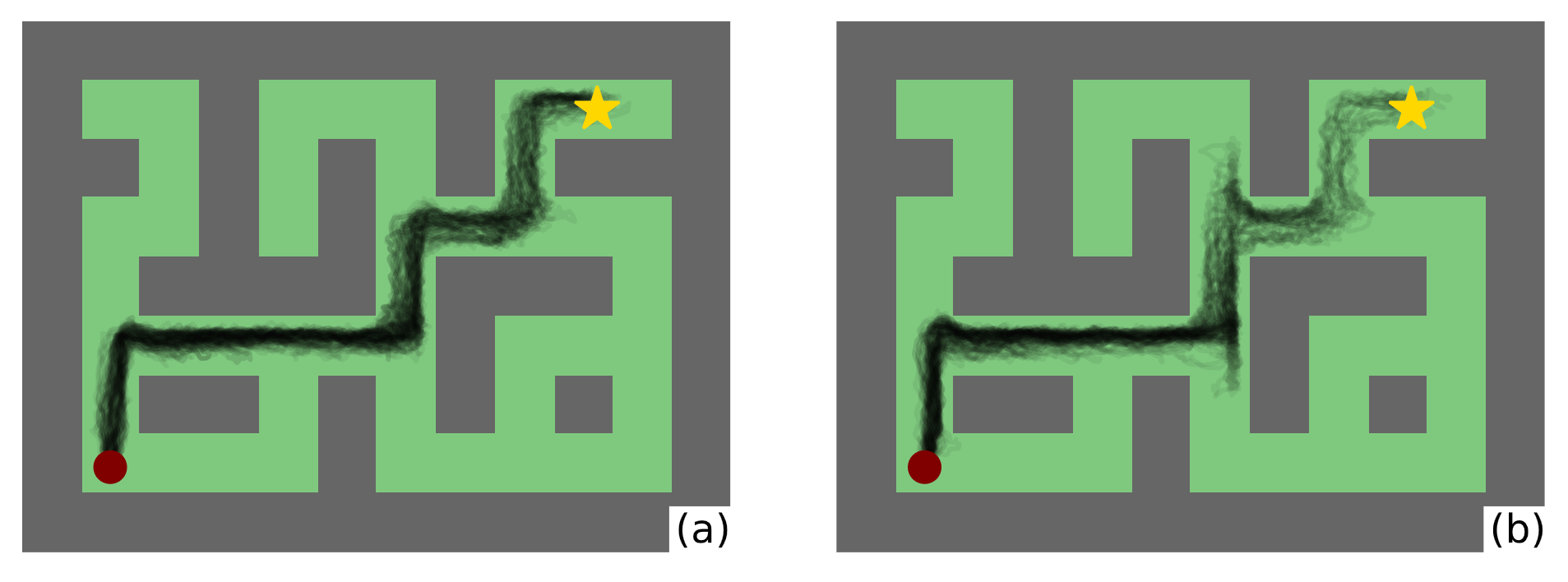
- We motivate the benefit of conditioning RvS on intermediate targets using a chain-MDP example and an empirical analysis of maze navigation tasks. By providing such additional guidance on suboptimal datasets, we show that a policy optimized with a behavioral cloning objective chooses more optimal actions compared to conditioning on fixed targets (as in Chen et al., 2021; Emmons et al., 2021), facilitating improved stitching capability.
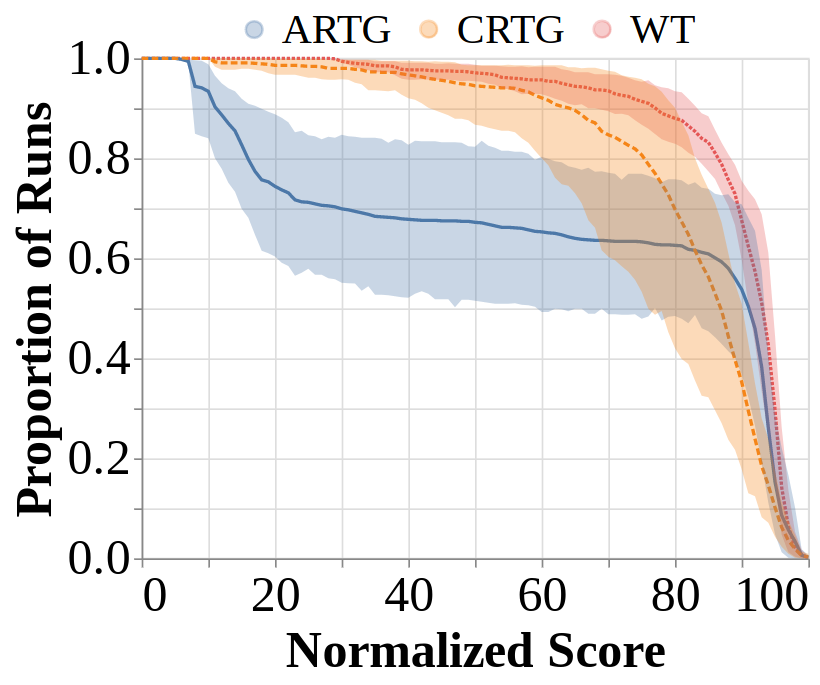
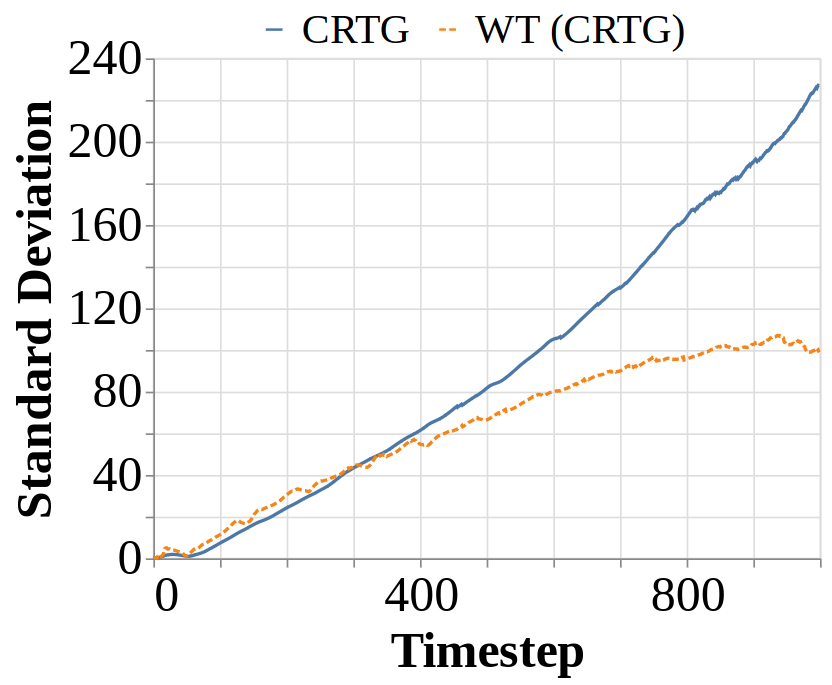
- Our work also provides practical insights for improving RvS, such as significantly reducing training time, solving the hyperparameter tuning challenge in RvS posed by Emmons et al., 2021, and notably improved stability in performance across runs.